


1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpiUmphu
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
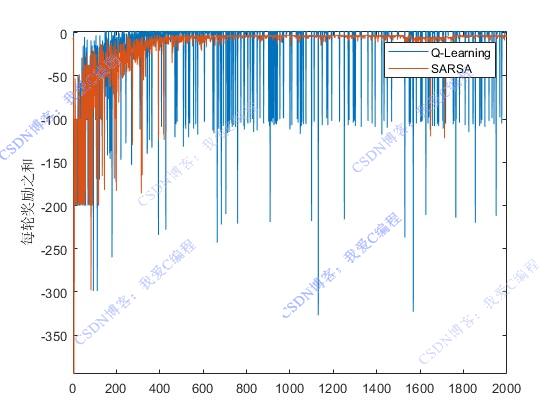
3.算法概述
强化学习(Reinforcement Learning, RL)是一种机器学习方法,它使代理(agent)通过与环境互动,学习采取何种行动以最大化累积奖励。在路径规划问题中,强化学习被用于自动探索环境,找到从起点到终点的最佳路径。其中,QLearning和SARSA是两种经典的价值迭代方法。
4.部分源码
.................................................................
% 保存每轮数据
step_save(iters) = step;
Rwd1(iters) = Rwd3;
Rwd2(iters) = Rwd3/step;
Rwd3 = 0; % 重置累积奖励
% 在到达目标后的额外步骤处理
[next, temp] = func_next(current, action, Maps,temp, Rm, Cm);
rewardNew = Rwd_stop;
if func_Overlap(next,xy1) ~= 0
if next.row == Rm && next.col >= 2 && next.col < Cm % 悬崖情况
rewardNew = Rwd_n;
next = xy0; % 回到起点
end
else
rewardNew = Rwd_p;
end
% 再次应用Epsilon-greedy策略
randN = 0 + (rand(1) * 1);
if(randN > Lsearch)
[~,nextAction] = max(Qtable0(next.row,next.col,:));
else
nextAction = round(1 + (rand(1) * 3));
end
nextQ = Qtable0(next.row,next.col,nextAction);
Qcur = Qtable0(current.row, current.col, action);
Qtable0(current.row, current.col, action) = Qcur + Lr * (rewardNew + Gma*nextQ - Qcur);
if iters == Miter
temp2 = func_Episode(Qtable0,Rm,Cm,xy0,xy1,Maps,Nact);
figure(2);
subplot(311);
plot(1:iters, Rwd1, 'b');
ylabel('每轮奖励之和')
axis([0 iters min(Rwd1)-10 max(Rwd1+10)])
subplot(312);
plot(1:iters, step_save, 'b');
ylabel('步数');
axis([0 iters 0 max(step_save+10)])
xlabel('试验次数')
subplot(313);
plot(1:iters, Rwd2, 'b');
ylabel('每轮奖励平均值')
axis([0 iters min(Rwd2)-10 max(Rwd2+10)])
drawnow
else
Qtable1=Qtable0;
end
iters = iters + 1; % 迭代计数器增加
end
save R2.mat
0Z_007m
---